 简单两步使用OpenVINO™搞定Qwen2的量化与部署任务
简单两步使用OpenVINO™搞定Qwen2的量化与部署任务
工具介绍
英特尔 OpenVINO 工具套件是一款开源 AI 推理优化部署的工具套件,可帮助开发人员和企业加速生成式人工智能 (AIGC)、大语言模型、计算机视觉和自然语言处理等 AI 工作负载,简化深度学习推理的开发和部署,便于实现从边缘到云的跨英特尔 平台的异构执行。
模型介绍
近期通义千问团队发布了其 Qwen 大模型的第二代架构 Qwen2,这是一个基于 Transformer 结构 decoder-only 模型,而 Qwen1.5 作为 Qwen2 架构的 Beta 版本,已经率先在 Hugging Face 及魔搭社区进行了发布。
Qwen1.5 版本本次开源了包括 0.5B、1.8B、4B、7B、14B 和 72B 在内的六种大小的基础和聊天模型,同时,也开源了量化模型。不仅提供了 Int4 和 Int8 的 GPTQ 模型,还有 AWQ 模型,以及 GGUF 量化模型。为了提升开发者体验,Qwen1.5 的代码合并到 Hugging Face Transformers 中,开发者现在可以直接使用 transformers>=4.37.0 而无需 trust_remote_code。此外,Qwen1.5 支持了例如 vLLM、SGLang、AutoGPTQ 等框架对Qwen1.5的支持。Qwen1.5 显著提升了聊天模型与人类偏好的一致性,并且改善了它们的多语言能力。所有模型提供了统一的上下文长度支持,支持 32K 上下文, 基础语言模型的质量也有所改进。

图:基于Optimum-intel与OpenVINO部署生成式AI模型流程
英特尔为开发者提供了快速部署 Qwen2的方案支持。开发者只需要在 GitHub 上克隆示例仓库[1],进行环境配置,并将 Hugging Face 模型转换为 OpenVINO IR 模型,即可进行模型推理。由于大部分步骤都可以自动完成,因此开发者只需要简单的工作便能完成部署,目前该仓库也被收录在 Qwen1.5 的官方仓库[2]中,接下来让我们一起看下具体的步骤和方法:
[1] 示例仓库:
https://github.com/OpenVINO-dev-contest/Qwen2.openvino
[2] 官方仓库:
https://github.com/QwenLM/Qwen1.5?tab=readme-ov-file#openvino
01
模型转换与量化
当您按仓库中的 README 文档完成集成环境配置后,可以直接通过以下命令运行模型的转化脚本,这里我们以 0.5B 版本的 Qwen1.5 为例:
python3 convert.py --model_id Qwen/Qwen1.5-0.5B-Chat --output {your_path}/Qwen1.5-0.5B-Chat-ov
这里首先会基于 Transformers 库从 Hugging Face 的 model hub 中下载并加载原始模型的 PyTorch 对象,如果开发者在这个过程中无法访问 Hugging Face 的 model hub,也可以通过配置环境变量的方式,将模型下载地址更换为镜像网站或者通过魔搭社区下载,并将 convert.py 脚本的 model_id 参数配置为本地路径,具体方法如下:
$env:HF_ENDPOINT = https://hf-mirror.com
huggingface-cli download --resume-download --local-dir-use-symlinks False Qwen/Qwen1.5-0.5B-Chat --local-dir {your_path}/Qwen1.5-0.5B-Chat
python3 convert.py --model_id {your_path}/Qwen1.5-0.5B-Chat --output {your_path}/ Qwen1.5-0.5B-Chat-ov
在完成模型下载后,该脚本会利用 Optimum-intel 库中的 OVModelForCausalLM .from_pretrained 函数自动完成对模型格式的转换,同时该函数也会根据用户指定的模型精度和配置信息,调用 NNCF 工具完成模型的权重量化。执行完毕后,你将获取一个由 .xml 和 .bin 文件所构成的 OpenVINO IR 模型文件,该模型默认以 int4+int8 的混合精度保存,此外你也可以通过配置 —precision,来选择不同的模型精度,例如 —precision int8或者 —precision fp16。
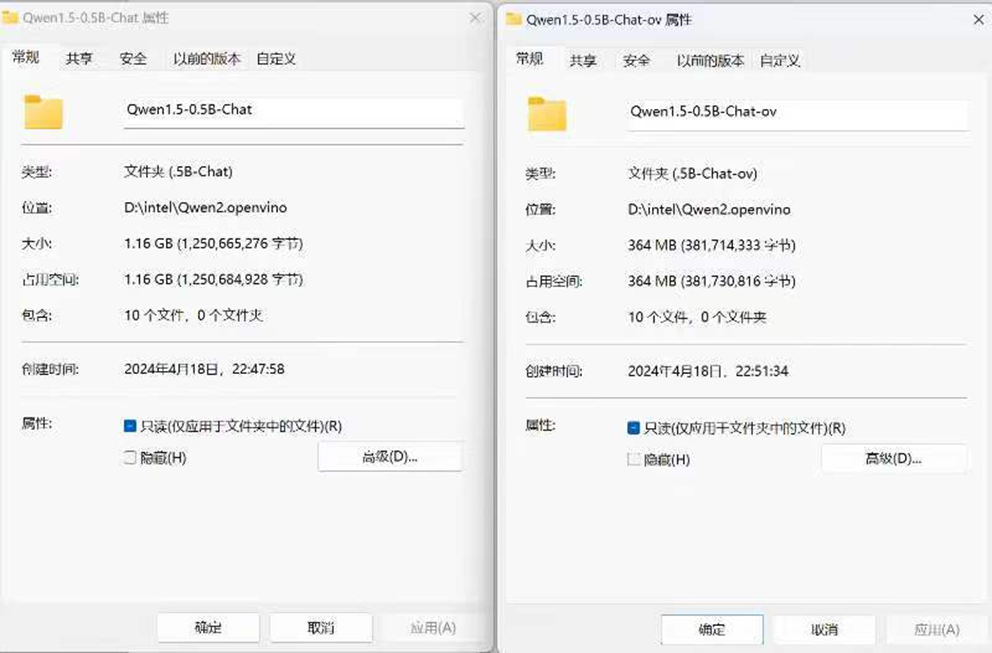
图:量化前后模型大小比较
可以看到相较原始 PyTorch 模型,经过 INT4 量化后的模型大小减少将近3/4。此外在这个过程中, int4+int8 量化比例也会自动打印在终端界面上,如下图所示。

图:量化比例输出
由于 OpenVINO NNCF 工具的权重压缩策略只针对于大语言模型中的 Embedding 和 Linear 这两种算子,所以该表格只会统计这两类算子的量化比例。其中 ratio-defining parameter 是指我们提前通过接口预设的混合精度比例,也就是 20% 权重以 INT8 表示,80% 以 INT4 表示,这也是考虑到量化对 Qwen1.5 模型准确度的影响,事先评估得到的配置参数,开发者也可以通过修改 Python 脚本中的默认配置调整量化参数:
compression_configs = {
"sym": False,
"group_size": 128,
"ratio": 0.8,
}
其中:
sym 为选择是否开启对称量化策略,对称量化会进一步提升模型运行速度,但也会在一定程度上降低模型准确性。
group_size为共享量化参数的通道数量,该值越大,压缩比也越高,反之,对模型准确性的影响越小。
ratio 则是 INT4 权重和 INT8 权重的混合精度比例。
更多可配置量化参数也可以参考 OpenVINO 官方文档[3]。如果遇到新模型,同时不知道如何选择量化参数以获取性能和准确度的最大平衡,开发者也可以通过这个示例[4]搜索出适合其他模型的量化参数。此外鉴于 LLM 第一层 Embedding layer 和最后一层操作对于输出准确度的影响, NNCF 默认会将他们以 INT8 表示,这也是为何在这个示例的 log 打印中,all parameters 显示的混合精度比例会有所不同。当然开发者也可以通过在量化参数中设置 “all_layers”: True,开关闭该默认策略。
[3] OpenVINO 官方文档
https://docs.openvino.ai/2024/openvino-workflow/model-optimization-guide/weight-compression.html
[4] 示例:
https://github.com/openvinotoolkit/nncf/tree/develop/examples/llm_compression/openvino/tiny_llama_find_hyperparams
02
模型部署
最后一步就是模型部署了,这里展示的是一个 Chatbot 聊天机器人的示例,这也是 LLM 应用中最普遍,也是最基础的 pipeline,而 OpenVINO 可以通过 Optimum-intel 工具为桥梁,复用 Transformers 库中预置的 pipeline,基于 OVModelForCausalLM 类中的 generate 方法,进行文本生成任务部署,以下为该脚本的运行方式:
python3 chat.py --model_path {your_path}/Qwen1.5-0.5B-Chat-ov --max_sequence_length 4096 --device CPU
如果开发者的设备中包含 Intel 的GPU产品,例如 Intel ARC 系列集成显卡或是独立显卡,可以在这个命令中将 device 参数改为 GPU,以激活更强大的模型推理能力。
在终端里运行该脚本后,会生成一个简易聊天对话界面,接下来你就可以验证它的效果和性能了。
Starting conversation
用户
你好
Qwen2-OpenVINO
你好!有什么我可以帮助你的吗?
用户
你是谁?
Qwen2-OpenVINO
我是来自阿里云的超大规模语言模型,我叫通义千问。
用户
请给我讲一个故事
Qwen2-OpenVINO
好的,这是一个关于一只小兔子和它的朋友的故事。
有一天,小兔子和他的朋友们决定去森林里探险。他们带上食物、水和一些工具,开始了他们的旅程。在旅途中,他们遇到了各种各样的动物,包括松鼠、狐狸、小鸟等等。他们一起玩耍、分享食物,还互相帮助解决问题。最后,他们在森林的深处找到了一个神秘的洞穴,里面藏着许多宝藏。他们带着所有的宝藏回到了家,庆祝这次愉快的冒险。
用户
请为这个故事起个标题
Qwen2-OpenVINO
"小兔子与朋友们的冒险之旅"
总结
通过模型转换量化+部署这两个步骤,我们可以轻松实现 在本地 PC 上部署 Qwen2 大语言模型,经测试该模型可以流畅运行在最新的 Intel Core Ultra 异构平台及至强 CPU 平台上,作为众多 AI agent 和 RAG 等创新应用的核心基石,大语言模型的本地部署能力将充分帮助开发者们打造更安全,更高效的 AI 解决方案。
审核编辑:刘清
-
英特尔
+关注
关注
60文章
9495浏览量
169155 -
人工智能
+关注
关注
1778文章
44242浏览量
231104 -
计算机视觉
+关注
关注
8文章
1605浏览量
45673 -
大模型
+关注
关注
2文章
1651浏览量
1252 -
OpenVINO
+关注
关注
0文章
61浏览量
95
原文标题:简单两步使用 OpenVINO™ 搞定 Qwen2 的量化与部署任务 | 开发者实战
文章出处:【微信号:英特尔物联网,微信公众号:英特尔物联网】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
如何使用OpenVINO C++ API部署FastSAM模型
低比特量化技术如何帮助LLM提升性能

英特尔CPU部署Qwen 1.8B模型的过程
基于keras利用cv2自带两步检测法进行实时脸部表情检测
【大联大世平Intel®神经计算棒NCS2试用申请】在树莓派上联合调试Intel®神经计算棒NCS2部署OpenVINO
2步搞定拼版!AD通用拼版技巧分享!
为什么无法通过Heroku部署OpenVINO™工具套件?
【爱芯派 Pro 开发板试用体验】模型部署(以mobilenetV2为例)
使用OpenVINO™ 部署PaddleSeg模型库中的DeepLabV3+模型

在C++中使用OpenVINO工具包部署YOLOv5模型
YOLOv8模型ONNX格式INT8量化轻松搞定

如何使用OpenVINO Python API部署FastSAM模型
NNCF压缩与量化YOLOv8模型与OpenVINO部署测试
简单三步使用OpenVINO™搞定ChatGLM3的本地部署






 工商网监
工商网监
评论